

The Resource Description Framework (RDF) is a (metadata) data model.
A core element of the model is the statement. A statement is a triple (s,p,o) consisting of a resource, a property, and the value of the property. The three elements of the triple are called, respectively, the subject, s, the predicate, p, and the object, o, of the statement. The object of a statement can be a resource or a literal.
A resource is primarily a Web resource, such as a Web page or an image linked to a Web page. However, resources do not need to be accessible on the Web. Physical objects, such as a sensing device, or abstract concepts may thus be resources. Generally, any entity that can be named by a URI is a resource.
A property is a relation used to describe a resource. It is named by a URI.
A literal is a value of primitive datatype, such as xsd:dateTime.
Building on an example, the following sections describe how RDF can be created from natural language sentences; how it can be improved, in order to take advantage of some of the RDF features; how RDF is typically visualized and serialized; and how it can be queried. Some of the well-known software tools and libraries are also mentioned.
Create
Natural language sentences can be understood as statements, and can be translated into RDF. Let’s look at an example.
My name is Markus Stocker and I live in Finland.
This sentence can be rephrased as two sentences, which are then translated into RDF statements. Depending on choices made, the translation can result in varying RDF, some of which may be considered “better.” First, let’s rephrase the sentence.
My name is Markus Stocker.
I live in Finland.
Now we have two sentences, each consisting of a subject, a predicate, and an object. In order to translate the sentences into RDF statements, we need to first come up with a few URIs. I am a physical object and I can assign myself a URI, say
http://markusstocker.com#me
Given the prefix hp: in place of http://markusstocker.com#, we can write the URI as
hp:me
Next, we need two URIs for the two predicates, say
ex:hasName
ex:livesIn
where ex: is the prefix for http://example.org#. The two objects, ‘Markus Stocker’ and ‘Finland’, are modelled as literals. We thus have the following RDF statements.
hp:me ex:hasName "Markus Stocker"
hp:me ex:livesIn "Finland"
Note that hp:me, ex:hasName, and ex:livesIn are global (universal) identifiers. I can share hp:me, for instance on my Web page, and others can reuse it and state things about me.
Improve
We can do better than this. First, “Markus Stocker” is a literal but it consists of two parts, a first name and a last name. Second, Finland is a country, and there are plenty of Web resources that tell more about Finland, such as Wikipedia. We could use the URL of one of them, as URI, and turn the literal “Finland” into a resource. The result could look as follows.
hp:me ex:hasName hp:name
hp:name ex:firstName "Markus"
hp:name ex:lastName "Stocker"
hp:me ex:livesIn http://en.wikipedia.org/wiki/Finland
Note that we now have a new resource, named hp:name, with two properties, ex:firstName and ex:lastName.
We can do even better. The Wikipedia URL for Finland returns an HTML document. That’s great for humans to read but not so much for computers to process. Ideally, the resource URI for Finland would return RDF. Instead of using the Wikipedia URL, it is better to use, for instance, the DBpedia URI for Finland or the GeoNames URI for Finland.
Let’s use the DBpedia URI for Finland, which is http://dbpedia.org/resource/Finland. I suggest you visit the link: do you recognize the RDF statements? Using the DBpedia URI for Finland we get
hp:me ex:hasName hp:name
hp:name ex:firstName "Markus"
hp:name ex:lastName "Stocker"
hp:me ex:livesIn http://dbpedia.org/resource/Finland
DBpedia tells us a lot about Finland, and it does so in RDF, which is great for computers to process. Among other things, it also tells us that the DBpedia URI for Finland is same as the GeoNames URI for Finland. We can write
hp:me ex:hasName hp:name
hp:name ex:firstName "Markus"
hp:name ex:lastName "Stocker"
hp:me ex:livesIn dbpedia:Finland
dbpedia:Finland owl:sameAs http://sws.geonames.org/660013
What just happened here? Well, by using the DBpedia URI for Finland, instead of the literal “Finland”, our small set of RDF statements just got a lot richer. For instance, we now know the population of Finland.
hp:me ex:hasName hp:name
hp:name ex:firstName "Markus"
hp:name ex:lastName "Stocker"
hp:me ex:livesIn dbpedia:Finland
dbpedia:Finland owl:sameAs gn:660013
gn:660013 gn:population "5244000"
In a nutshell, we link RDF data across distributed systems. It is a bit like Web pages link to other Web pages, images, videos, PDF documents. With RDF we link data, rather than documents.
Visualize
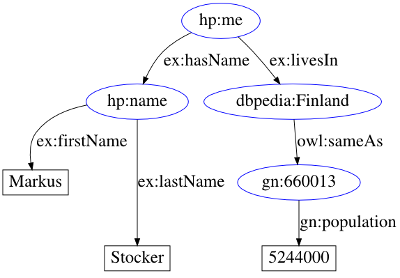
A RDF statement can be represented graphically as two nodes and a directed arc. The two nodes are for the subject and object, respectively, of the statement. The arc is for the property and is directed from the subject to the object. A set of statements forms an RDF graph. The following figure is an example that corresponds to our RDF statements. Read the graph from the top and follow the arrows to reconstruct the RDF statements.
Serialize
There exist various syntaxes for RDF, including RDF/XML. The following is an XML document contaning our RDF statements.
<?xml version="1.0" encoding="utf-8"?>
<rdf:RDF
xmlns:dbpedia="http://dbpedia.org/resource/"
xmlns:ex="http://example.org#"
xmlns:gn="http://sws.geonames.org/"
xmlns:hp="http://markusstocker.com#"
xmlns:owl="http://www.w3.org/2002/07/owl#"
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#">
<rdf:Description rdf:about="http://markusstocker.com#me">
<ex:hasName rdf:resource="http://markusstocker.com#name"/>
<ex:livesIn rdf:resource="http://dbpedia.org/resource/Finland"/>
</rdf:Description>
<rdf:Description rdf:about="http://markusstocker.com#name">
<ex:firstName>Markus</ex:firstName>
<ex:lastName>Stocker</ex:lastName>
</rdf:Description>
<rdf:Description rdf:about="http://dbpedia.org/resource/Finland">
<owl:sameAs rdf:resource="http://sws.geonames.org/660013"/>
</rdf:Description>
<rdf:Description rdf:about="http://sws.geonames.org/660013">
<gn:population>5244000</gn:population>
</rdf:Description>
</rdf:RDF>
If you look carefully, you will spot the same triples. For instance, the triple
hp:me ex:livesIn dbpedia:Finland
is equivalent to
<rdf:Description rdf:about="http://markusstocker.com#me">
<ex:livesIn rdf:resource="http://dbpedia.org/resource/Finland"/>
</rdf:Description>
Syntaxes have various pros and cons. Some are more readable to humans others are easier to process by machines. Some require less space than others.
Query
SPARQL is a declarative query language for RDF. It’s core construct is the triple pattern. A triple pattern has the same subject, predicate, object structure as the RDF statement. However, each of the triple elements may be variable. Thus, the following are two triple patterns and the subject of the second is variable (?s).
hp:me ex:livesIn dbpedia:Finland
?s ex:livesIn dbpedia:Finland
One or more triple patterns form a basic graph pattern. A SPARQL query engine matches such graph patterns against an RDF graph and returns solutions with variable bindings, e.g.
?s = hp:me
SPARQL is an expressive query language and has many features, including optional patterns, filtering, sorting. The specification describes SPARQL in full.
Let’s look at an example. The following SPARQL query returns the population where Markus Stocker lives in.
prefix dbpedia: <http://dbpedia.org/resource/>
prefix ex: <http://example.org#>
prefix gn: <http://sws.geonames.org/>
prefix hp: <http://markusstocker.com#>
prefix owl: <http://www.w3.org/2002/07/owl#>
select ?population
where {
?s ex:hasName ?n .
?n ex:firstName "Markus" .
?n ex:lastName "Stocker" .
?s ex:livesIn ?l1 .
?l1 owl:sameAs ?l2 .
?l2 gn:population ?population .
}
Between curly parenthesis, there are six triple patterns, which form the basic graph pattern of the query. A SPARQL query engine matches this pattern against RDF data (graph) and creates solutions with variable bindings. Each solution includes bindings for all variables in the SPARQL query. However, the query selects only ?population and will thus return only this binding.
Note the joins between triple patterns. For instance,
?s ex:hasName ?n
?n ex:firstName "Markus"
share the variable ?n in object and subject position, respectively. Thus, RDF data that matches the two triple patterns must share the same URI for the ?n binding. This creates a join. There are several other joins in the example query.
Tools
RDF is not meant for humans to read and write. It is meant for computers to process. There are plenty of tools and frameworks that read, process, and write RDF. Many are open source and available for free and the following list is merely indicative.
Popular Java frameworks are Apache Jena and Sesame. RDF can be processed using various other programming languages, including Python, Perl, C#, C (just google RDF [your favorite language]). There exist various RDF databases, including Stardog, Profium Sense, and plenty of others. As we will see in the next section, there exist also online tools. On the command line, Raptor can be handy.
Exercises
-
Let’s use an online RDF translator to convert RDF syntaxes. First, open the previous link in a new browser tab. On the Web page, select the “Input Field” tab. Then copy our example RDF/XML and paste it into the input field. Below the input field, choose any of the output formats, for instance N-Triples and then submit. You can play around with various input/output syntaxes (note that you may need to specify the input syntax, if the tool fails to automatically recognize it).
-
Try to execute our SPARQL query on the RDF/XML data. To execute the SPARQL query you can use one of the discussed tools, such as Apache Jena. However, a SPARQL query engine that is available online is easier for a quick test. Open the previous link in a new tab and select “Import RDF Data”. Choose “from text” and paste the example RDF/XML data into the text area (“File:”). Hit the “Upload” button. The system will tell you that the file was uploaded and it will return you a “Graph:”. You’ll need to copy that URI, something like
http://local.virt/DAV/VAD/sparql_demo/data/user_data/...till the end of the line. Then select “Query Processor” from the menu on the left. Removehttp://demo.openlinksw.com/sysfrom the input field below “Graph” and paste the URI you copied before. Then remove the content of the “SPARQL Query” text area and paste the example SPARQL query. Finally, hit the “Run Query” button. You should get5244000as binding value for the?populationvariable. Try to modify the SPARQL query, for instance, use the variable?lastnamefor the value ofex:lastName(instead of “Stocker”) and modifyselectto include the variable, e.g.select ?lastname ?population.
This post is the first of a series. The next post introduces RDFS and OWL.